
Detecting Evasive PDF Malware: A Comparative Analysis of Advanced Machine Learning Approaches
(Accepted for IEEE QPAIN 2025 and possible inclusion in IEEE Xplore Digital Library, and indexed by Scopus and other indexing services.)
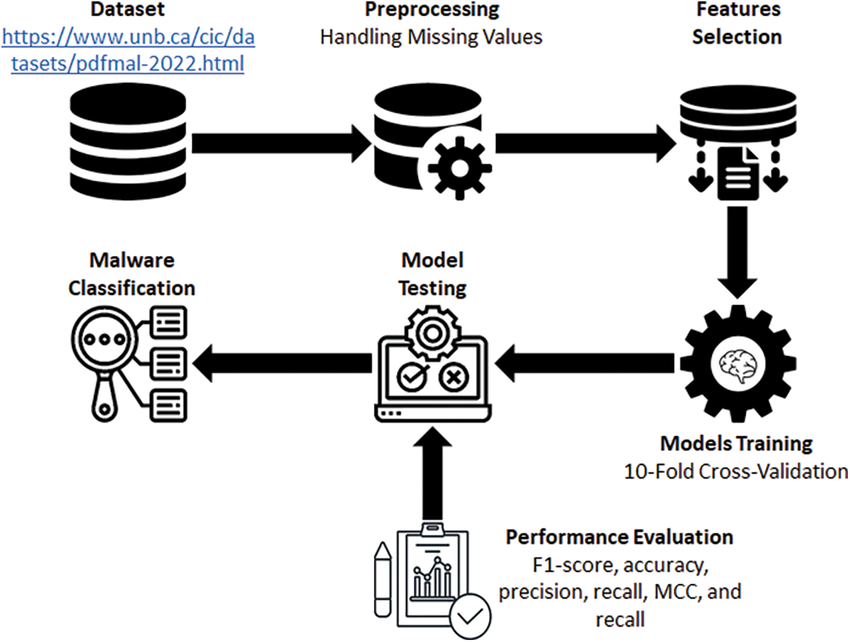
Abstract—Portable Document Format (PDF) files remain a prevalent vector for malware distribution due to their ubiquity and complex structure that can conceal malicious code. The evolution of PDF malware has led to increasingly sophisticated evasion techniques that bypass traditional detection systems. This paper presents a comprehensive evaluation of five machine learning approaches—K-Nearest Neighbors, Random Forest, Logistic Regression, XGBoost, and Convolutional Neural Networks—for identifying evasive PDF malware using the CIC-Evasive-PDFMal2022 dataset. This dataset uniquely incorporates samples specifically designed to evade detection by exhibiting characteristics dissimilar from their true class. Our experimental results demonstrate that ensemble methods, particularly XGBoost, achieve superior performance with 99.05% accuracy in detecting malicious PDF files, even those employing advanced evasion techniques. We analyze the effectiveness of various preprocessing techniques and feature representations that contribute to robust detection performance. The findings suggest
that combining structural analysis with advanced machine learning approaches provides a promising framework for countering the evolving landscape of PDF-based threats in contemporary cybersecurity environments.